Алгоритмизация и Программирование
Морозов Владимир Игоревич
Простейшие структуры данных
Определение
- Структура данных (англ. data structure) — программная единица, позволяющая хранить и обрабатывать однотипные и/или логически связанные данные
- Для добавления, поиска, изменения и удаления данных структура данных предоставляет некоторый набор функций, составляющих её интерфейс
- Структуры данных описывают способ хранения однотипных данных вне зависимости от вида самих данных
Цель
- Цель структур данных — упростить моделирование задач обработки данных
- Большинство данных из практических задач может быть сведено к некоторым уже известным структурам данных
- Это избавляет от необходимости разрабатывать новые алгоритмы для каждой новой задачи
Виды структур данных
Структуры данных по реализации делятся на два вида:
- Смежные структуры данных реализованы в виде непрерывных блоков памяти. К ним относятся массивы, матрицы, кучи и хэш-таблицы.
- Связные структуры данных реализованы в отдельных блоках памяти, связанных вместе с помощью указателей. К этому виду структур данных относятся списки, деревья и списки смежных вершин графов.
Массив
- Массив представляет собой основную структуру данных смежного типа
- Записи данных в массивах имеют постоянный размер, что позволяет с легкостью найти любой элемент по его индексу (зная адрес первого)
- Т.к. массив является смежным типом данных, его элементы располагаются в смежных ячейках памяти последовательно друг за другом
Массив
Пример на C++:
int arr[6] {10, 15, 16, 8, 9, 1};
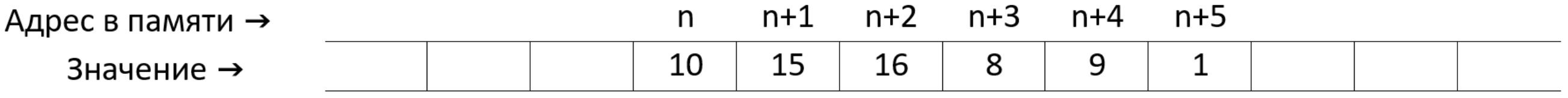
Преимущества массива
- Постоянное время доступа при условии наличия индекса
- Так как индекс каждого элемента массива соответствует определенному адресу в памяти, то при наличии соответствующего индекса доступ к произвольному элементу массива осуществляется за $O(1)$
Преимущества массива
- Эффективное использование памяти
- Массивы содержат только данные, поэтому память не тратится на указатели и другую форматирующую информацию
- Кроме этого, для элементов массива не требуется использовать метку конца записи, т. к. все элементы массива имеют одинаковый размер
Преимущества массива
- Локальность в памяти
- Одна из самых распространенных идиом программирования — обработка элементов структуры данных в цикле
- Массивы хорошо подходят для операций такого типа, поскольку обладают отличной локальностью в памяти
- В современных компьютерных архитектурах физическая непрерывность последовательных обращений к данным помогает воспользоваться высокоскоростной кэш-памятью
Вычислительная сложность
- Массивы подразделяются на статические и динамические
- Отличие динамических в том, что они допускают добавление элементов
- Таблица вычислительной сложности представлена для динамического массива
Вычислительная сложность
| Операция | Вычислительная сложность |
|---|---|
| Получение по индексу | $O(1)$ |
| Вставка (или удаление) в начало | $O(N)$ |
| Вставка (или удаление) в середину | $O(N)$ |
| Вставка (или удаление) в конец | $O(1)$ — амортизированная |
Связный список
- Связный список — базовая динамическая структура данных в информатике, состоящая из узлов, содержащих данные и ссылки («связки») на следующий и/или предыдущий узел списка
- Т.к. каждый узел списка содержит указатель на следующий (т.е. адрес его расположения в памяти), элементы списка могут храниться в любых случайных местах в памяти независимо друг от друга
Пример
Для примера рассмотрим связный список из трёх элементов: $21$, $55$, $46$. Логически он выглядит так:

А в памяти может располагаться, например, так:

Вычислительная сложность
- Связные списки подразделяются на односвязные и двусвязные
- В двусвязных каждый элемент указывает не только на следующий, но и на предыдущий
- Временная сложность представлена для двусвязного списка
Вычислительная сложность
| Операция | Вычислительная сложность |
|---|---|
| Получение по индексу | $O(N)$ |
| Вставка (или удаление) куда (откуда) угодно, если известен указатель | $O(1)$ |
Абстрактные типы данных
- Абстрактный тип данных (АТД) — это математическая модель для типов данных, где тип данных определяется поведением (семантикой) с точки зрения пользователя данных, а именно в терминах возможных значений, возможных операций над данными этого типа и поведения этих операций
- Один и тот же абстрактный тип данных может быть реализован по-разному
Абстрактные типы данных
- Реализация описывается как набор других АТД и алгоритмов для каждой операции и называется структурой данных
- Структура данных может быть реализована на выбранном языке программирования (в виде класса)
Стек
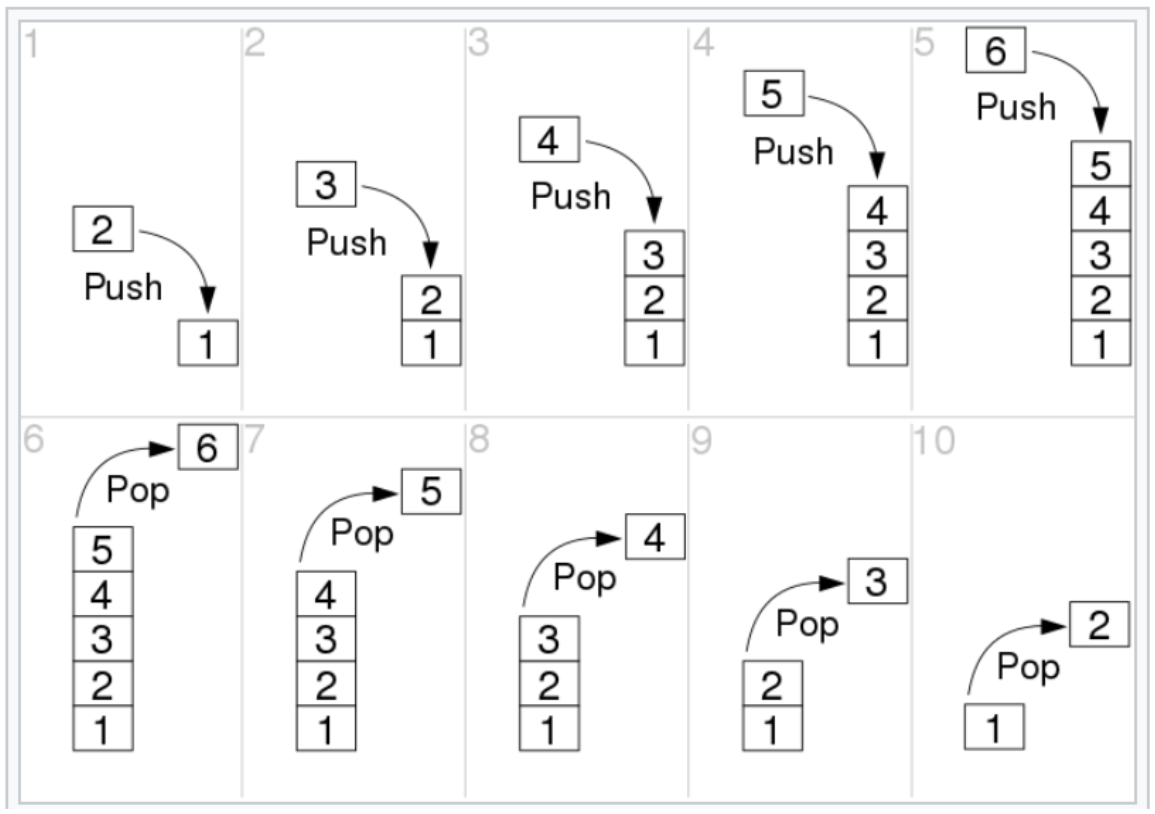
- Стек (Stack) — абстрактный тип данных, реализованный по принципу LIFO — Last In First Out — кто последним вошёл, тот первым вышел
-
Интерфейс стека состоит из двух основных операций:
- $push$ — загрузить элемент в стек
- $pop$ — выгрузить элемент из стека
Стек
Очередь
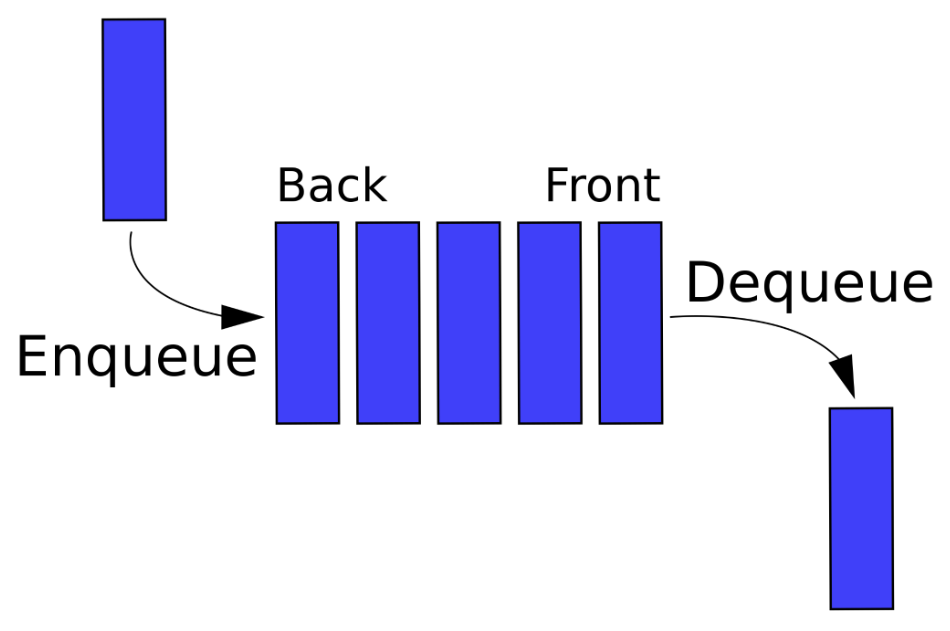
- Очередь (Queue) — абстрактный тип данных, реализованный по принципу FIFO — First In First Out — кто первым вошёл, тот первым вышел
-
Интерфейс очереди состоит из двух основных операций
- $enqueue$ — загрузить элемент в начало очереди
- $dequeue$ — выгрузить элемент с конца очереди
Очередь
Дек
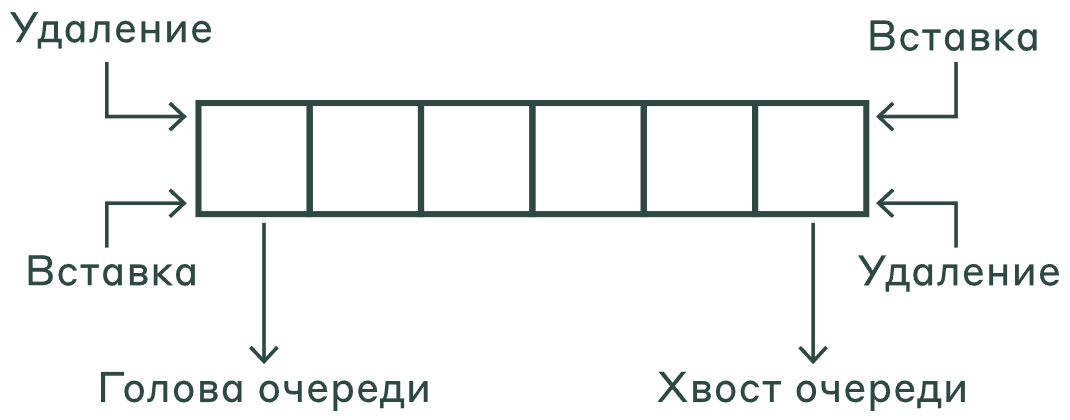
- Дек (Double-Ended Queue) — абстрактный тип данных, реализованный так же, как очередь, но с возможностью загрузки и выгрузки с обеих сторон
Реализация в C++
| Структура | Реализация |
|---|---|
| Динамический массив | std::vector |
| Односвязный список | std::forward_list |
| Двусвязный список | std::list |
| Стек | std::stack |
| Очередь | std::queue |
| Дек | std::deque |
Полезные источники
- RU Томас Х. Кормен, Чарльз И. Лейзерсон, Рональд Л. Ривест, Клиффорд Штайн. Алгоритмы: построение и анализ, 3-е издание. Глава 10 — Основная книга нашего курса.
- RU С. Скиена. Алгоиртмы. Руководство по разработке. 2-е издание. Разделы 3.1, 3.2 — Более простое и краткое объяснение.